December 30th 2022
During the design phase, I knew that Python would be slow compared to lower-level languages. In anticipation of performance issues down the road, parallelism was incorporated into the design from the start. It didn't take long to reach the point where backtesting with short-interval intraday data began to hit the limits of a single server. Forking using Python's built-in multiprocessing helped for some time, but soon even that was not enough. So it became necessary to be able to expand horizontally with a microservices-based approach. The problem was how to coordinate tasks between the microservices - some form of message broker was going to be needed. Initially I ran some tests with the major pre-existing libraries out there: RabbitMQ, Celery, and Apache Kafka. After a few days of experimentingm each one felt like using a sledgehammer to crack a nut. I didn't need a heavy-duty solution, just a light and nimble tool to unite a minimal number of services. ZMQ seemed like a good fit; it didn't require any additional infrastructure to be created, the documentation was great, and it had a reputation for being reasonably fast. I asked around in a few Slack groups and some of the more senior members had used it in their own projects to good effect.
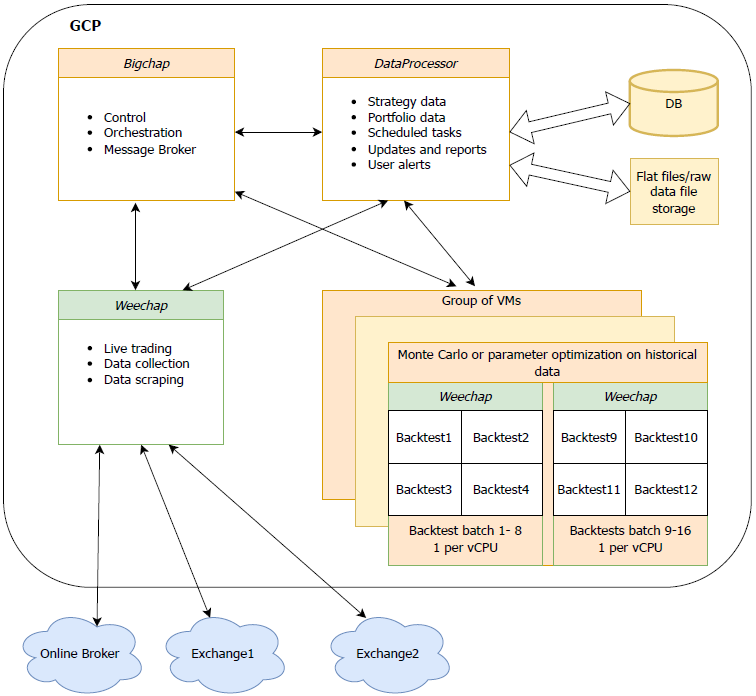
High-level components with all the fiddly bits omitted
ZMQ is not a message queue broker per-say, but more of a socket-based framework. ZMQ allowed for a lean intial messaging setup, and as development progressed more functionality was added. I settled on three custom main services: Bigchap, Weechap, and the DataProcessor (excluding services for common functionality like logging and infrastructure). The proof of concept showed to me the importance of defining protocol standards - it was easy to get lost and lose hours debugging something which would be simple to fix if everything ran on a single server. So the Distributed class was created to abstract away some of the underlying ZMQ complexity, a reliable framework to ensure that each service is sharing the base logic. Each service inherits from this , and it hides away common messaging functionality like message timeouts, recovery from dropped messages, and sequence error handling.
Integrated into the Distributed class is a simple way to ensure that distributed trading-related tasks are kept simple: each one is broken into discrete steps using state machines. Each state machine has clearly defined entry and exit points. As a conceptual example if one service is in the 'await-buysells' state, the only transitions that are allowed to progress to the next state would be 'ack-buysells', or 'timeout-buysells' (which would then prompt the generating service to ask for a status update). The Python state machine library Transitions was used to implement these, although a more platform agnostic method might more sense in future. It requires a bit of pre-plannng to implement a task in this format, but this helps to keep each one clean and simple, and debugging becomes a lot easier. Each task has a unique ID shared across nodes which simplifies tracking a task through the aggregation solution.
More details on each service:
Bigchap - This is a mix between a message broker and a control center. It is only concerned with passing messages as fast as it can and offloads most processing to other modules. It is responsible for:
Weechap - The name of the worker module that acts as a wrapper around the low level tasks. There are many of these running at once, continually sending status updates back to the Bigchap and data back to the DataProcessor for storage. It is responsible for:
DataProcessor - this has two purposes - handling storage and retrieval of all strategy and task data to the main database, and also any simple tasks that can work with this data without requiring to go through the full processing pipeline via wokers (Weechaps). It is responsible for:
The above design allows the worker services (Weechap's) to be staged remotely, close to exchanges if necessary. This enables faster execution and lower latency; to help be near the front of the queue as much as possible while trading . Splitting the database service (DataProcessor) and the main processing service (Bigchap) might have been over-engineered, and they could have been combined which would work just fine. As the project becomes more sophisticated, hopefully the decision to seperate them will be proven to have been a precient one.